

Last Saturday, all the law school-bound folks who took the November LSAT were treated to the best weekend plans one could hope for: staring at a screen all day, nervously awaiting the score release email from LSAC.
When that email finally comes, pretty much everyone acts the same way. Like the children who make a beeline to the present under the Christmas that they just instinctively know contains the dopest toys, ignoring all the presents that probably contain, like, socks and sweaters — these test takers go straight to the score, and discard all the other stuff provided in the score release emails for disclosed exams.
But for LSAT instructors, we savor the other stuff — the actual exam, the answer sheets, the score conversion table — I’m getting inappropriately flush just thinking about it. In fact, past end-of-year exams were typically held in early December, so the score release date ended up being around Christmas time, which would lead to the inevitable joke that the release of a new LSAT really is the best part of Christmas morning for the brother- and sisterhood of social pariahs who teach this exam.
But, since they moving the end-of-year LSAT up to November, the score release didn’t fall on Christmas this year. Instead, they fell on the sixth day of Hanukkah. Which is apt, because feeling like you don’t have enough fuel to power you through, but somehow, miraculously, making it to the end is a feeling every LSAT taker can relate to.
At any rate, now that we have the November LSAT, and — as we do for every disclosed exam –we’re going to go through it with the attentiveness of a Talmudic scholar. We’ll be giving our impressions of each section of the exam and the “curve”, to try see how this exam compares to other recent exams and if there are any on-going trends that this test exemplifies.
All right, enough pre-amble. Let’s start with some Logical Reasoning …
Logical Reasoning
• Let’s start with the question distribution. Based on Blueprint’s classification system, there are three general families of questions, and several types of questions within each family. The LSAT always has its favorite questions that it tests extensively, but the prevalence of other question types wax and wane depending on the vicissitudes of the test writers. So looking at recent the question distribution of recent LSATs can give you a good sense of how many questions of each type will appear on future exams. For the November 2018 exam, here’s the question-by-question breakdown, compared to the average frequency of that question type, based on all the published LSATs since 2013.
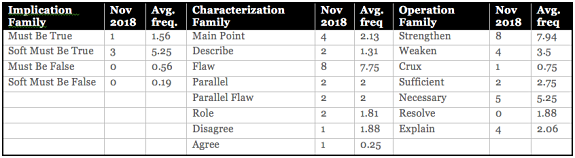
As you can see, most question types are at least somewhere close to their average frequency. The aberrations on this exam were Soft Must Be True and Main Point questions. You usually get somewhere between four and six Soft Must Be True questions, but this exam had a paltry three. But that’s not entirely out of the blue — the test writers have been de-emphasizing Implication Family questions on recent exams, so it’s not entirely surprising that the most prominent Implication question took a hit here. Personally, I would view that as good news. I think these Soft Must Be True questions are the most difficult question type in Logical Reasoning. And, not coincidentally, I thought one of the hardest questions on this exam’s Logical Reasoning section was a Soft Must Be True question (it was about nerve cell regeneration).
There was an abnormally high number of Main Point questions. Also good news, imho, as I think these are typically among the easier question types on the LSAT.
Oh, and just for “fun,” would you like to see some slightly chaotic charts on how frequently these question types have appeared on the last ten published LSATs? No? Oh … well, I made them anyway, so, here they are …
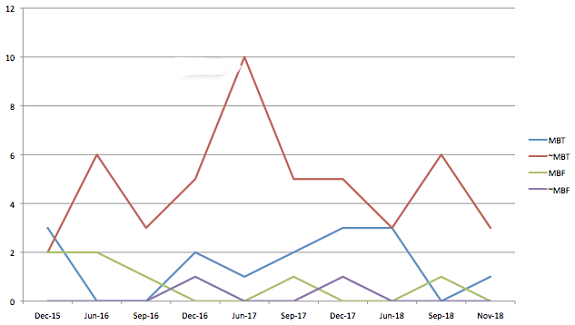
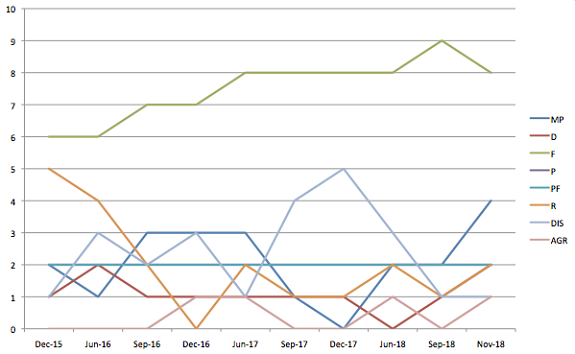
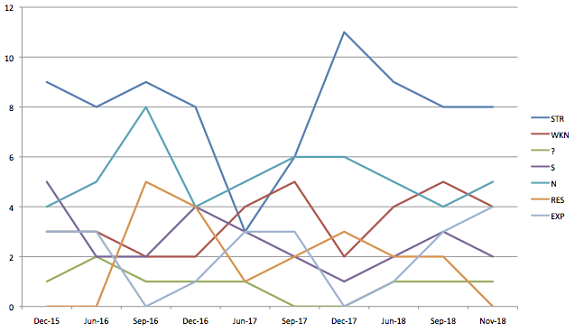
Another thing to note: in 2016 and ’17, for whatever reason, the test writers went crazy for Disagree and Agree questions. They used to only include one or two of these on each exam, but in 2016-17, they started including three, four, or five. We thought at the time that the Disagree question would be prominently featured on future exams, too. I thought this was a fitting tip of the cap to our polarized national discourse, in which we can’t seem to agree on anything, and a canny way to test future law students’ ability to characterize a point at issue between two parties — a skill that’s essential to reading a legal case in law school. But, alas, a year later, this doesn’t really appear to be the case. Farewell, Disagree prominence, we hardly knew ye.
• With respect to the content of these questions, we saw a pretty standard slate of concepts. I counted eight questions that involved conditional statements (almost of which were clustered in one of the two Logical Reasoning sections, for whatever reason, and almost none of which were especially convoluted or difficult), four that involved causation, and a veritable holiday smorgasbord of common fallacies. Causation fallacies, comparison fallacies, whole to part fallacies, percent versus amount fallacies, equivocations, exclusivity fallacies, absence of evidence fallacies, and logical force fallacies all reared their ugly heads throughout the two LR sections.
A curious trend on recent LSATs is that certain tests have really repeated one of the common fallacies, over and over again. In September, we saw a proliferation of the perception versus reality fallacy. In June, we saw a bunch of bad comparisons. Last December, there was a lot causation fallacies. On this November exam, there were a lot of equivocations. Which is just a fancy way of saying that someone assumes that two related concepts are completely interchangeable, when maybe they aren’t.
For instance, in one early Weaken question, a bat apologist named Pratt assumed what was true of bats was also true of rabid bats. Pratt the Batt Guy said that while rabid animals pose a danger to humans, bats rarely bite people and most bats don’t have rabies. He concludes that health regulations that urge people to remove bats residing in buildings where people live or work are unjustified. Which, like, first — and this should really go without saying –you shouldn’t voluntarily live or work with bats. Unless you’re a billionaire detective haunted by your parents’ murder and sharing city space with a grotesquerie of deranged villains, that’s weird. These health warnings are self-justifying. Second, this dude assumes just because bats in general don’t bite that rabid bats won’t bite either. Sure, bats and rabid bats are related — they are the same animal — but there are important differences between the two (like, say, only one has a foamy mouth, a swelling brain, and — importantly — violent, erratic movements symptomatic of rabid mammals). We would say Pratt is equivocating between bats and rabid bats, by assuming that they act the same. The right answer merely pointed out a salient difference: that rabid bats are more aggressive than uninfected bats.*
*The common fallacies have a fair amount overlap, so you can usually say that one argument commits multiple common fallacies. We could also have said this argument was relying on a faulty analogy between bats and rabid bats.
And one very specific type of equivocation showed up a bunch: confusing a comparative and an absolute claim. I might say that it has become safer to eat Romaine lettuce in recent months (that’s a comparative claim). But to assume that now Romaine lettuce is safe to eat (an absolute claim) would be a, quite literally, deadly equivocation. The writers of this exam seemingly love to test this concept, given how often it shows up. So they must have had a dang ball coming up with the questions on this one.
There was a question in which an aesthete claimed that abstract expressionist paintings were “aesthetically pleasing” based on the fact that most people found those “more aesthetic pleasing” than a dumb child’s painting. There was another question in which a pesticide-loving farmer claimed we can’t increase the number of farmers who practice organic farming because if all farmers practiced organic farming we wouldn’t produce enough food to feed the population. That farmer must have inhaled a bit too many chemicals over the years. Another argument assumed that because all vacations reduce the burn out experienced on the job, that multiple short vacations reduce worker’s burn out more than one long vacation.
• All right, this is the space where I get to chat about my favorite question** and my least favorite.
**Hey … don’t look at me like that. I may be a nerd who actually has favorite questions, but I’m still a human being who has dignity and deserves respe … wait wait wait — where are you going? Come back …
First, the favorite. I got to hand it to the test writers on a difficult Explain question that came at the end of the second LR section, even if my notes on that question include the phrase, “This was f[letter redacted]cking stupid.” They really came up with a creative way to explain the situation at hand. The situation is thus: a new antitheft device is on the market for cars. It relies on electronic homing beacons which allow authorities to track stolen cars, and it’s so effective that it’ll help police catch even the most experienced car thief. Except like no one has the device yet and the device’s presence is undetectable to a car thief so, unlike The Mighty Club of Yore, it doesn’t “directly deter theft.” Nonetheless, auto thefts drop dramatically, even in cities where very few people have the device.
How can we explain this difference? Well, I, along with what I imagine was a sizable percentage of test takers, assumed that even if wasn’t “directly” deterring theft — as in, car thief sees device, decides not to steal car — the possibility that any car stolen could have that device has an indirectly deterrent effect. So, you know, the thieves are compelled to give up the now-too-dangerous life of car thieving and, I don’t know, learn how to code? But of course, no answer choice said that. Not even close.
I was able to eliminate every wrong answer except the last, which said, “In most cities, the majority of car thefts are committed by a few very experienced car thieves.” I stared at it for minutes, trying to wrap my head around it. It seemed so stupid to think about there being this small network of hyper-competent car thieves. This is bad Nicolas Cage movie territory. But if there are only a few thieves doing all of the thieving, all this device has to do is take out one or two of them to have a dramatic effect on the number of stolen cars. If the device allows the authorities to catch just one Randall “Memphis” Raines, a prolific car thief is taken off the streets, and cars are much less likely to be stolen in the future. Instead of needing many devices equipped to many cars to catch many thieves, we just need a few devices in a few cars to catch a few thieves. At the very least, I have to appreciate the test writers getting creative and giving a cinematic approach to this Explain question.
Now, sadly, the least favorite: a difficult Flaw question, late in the first LR section on the released exam. This question is a little tricky as far as these things go, but not anything crazy overwhelming. There was study in which 500 families were given a medical self-help book and 500 comparable families were not. You know, how to treat a common abrasion, how to suture a knife wound, how to perform a makeshift, DIY appendectomy. Stuff we want untrained professionals handling. We’re told that doctor visits among families who were given the book dropped by 20%, but there was no change in the frequency of doctor visits for families not given the book. Great, we have correlation. Now, if the conclusion said “The experiment indicates that having a medical self-help book in the home decreases the frequency of doctors visits,” we have a classic correlation-does-not-imply-causation situation.
Except the right conclusion didn’t quite do that. It said, “[T]he experiment indicates that having a medical self-help book in the home improves family health.” There was also another premise that said, “[I]mproved family health leads to fewer visits to doctors.”
If I were to ask you, right now, if we have any evidence that the families who had the medical self-help book were in better health than they were before, I think you’d say, “No.” And you’d be right. We only have evidence that they’re going to the doctors less. They could actually be in worse health, if they’re doing a bad job relying on the medical self-help book. These families could be walking around with infected wounds and misdiagnosed maladies, for all we know. This argument is a causation fallacy, but it’s also equivocating (there that word is, again) between fewer doctors visits and improved health.
It’s not the hardest argument to understand. But it really sticks in my craw when the LSAT decides to make a question harder just by making the answer choices pointlessly abstract. Like, I know legal jargon is abstruse and hard-to-follow and this test is a way for law schools to get a sense of how well prospective students can handle that language, but I don’t remember anything as circuitous as, “two different states of affairs could each causally contribute to the same effect even though neither causally contributes to the other.”
When you’re confronted with a crazy abstract answer choice like this one, try to plug in the actual concepts from the stimulus to help you make sense of the answer choice. The two “states of affairs,” I guess, are having a self-help book and having improved health. According to the argument, both of those lead to fewer doctor visits. So, if we replace the abstractions with a concrete nouns, it would be, “Having a self-help book and improved health could both contribute to fewer doctor visits, even though having a self-help book might not cause improved health.” Reading it that way, I think, makes it plain that this is the correct answer. Sure, having a self-help book would lead to fewer doctor visits. And sure, being in better health would lead to fewer doctor visits. But that doesn’t mean that the self-help book is leading to the better health, which in turn leads to fewer doctor visits.
Even on other annoyingly abstract questions like this one, you can get through it. Just fill in the abstract terms with the nouns from the stimulus. And, by the way, you should be doing this a lot on the LSAT. On this test, there’ll be more Mad Libs than the 2016 Democratic National Convention.
Reading Comprehension
• Next up, everyone’s no one’s favorite section, Reading Comp. Reading Comp being the most difficult section on an exam has been rule and not the exception lately. This section, though … I thought it was pretty mild. Until I got to that last passage. Things were going great, until someone brought up the damn cosmos again and we got another passage on the Big Bang and the multiverse and entropy and all that stuff that was also on a difficult passage from December 2017.
• So let’s go over that final passage. You’d think that after a recent passage about this very topic on the December 2017 exam, this wouldn’t be too difficult. But there were a few annoying things this passage did, which I will dutifully catalogue for you. Before that, though, what was this passage about? The passage starts by conveying the consensus view among scientists that the universe started off like Jon Snow … tiny, hot, and dense. And then the Big Bang happened and the universe has expanded and cooled. But some physicists, namely Sean Carroll and Jennifer Chen, believe there were multiple Big Bangs*** that created multiple universes. According the second law of thermodynamics, entropy and chaos should increase overtime (this author includes a not-at-all helpful analogy to help illustrate that idea). So it doesn’t make sense that the universe started very hot and dense, since means there’s not a lot of chaos or entropy (apparently the term “hot mess” is an oxymoron), and a low entropy-starting point is very improbable. Carroll and Chen argue instead that the universe probably started out a cold and empty place.**** But, in that case, how did the universe expand? Usually you’d expect hot, dense things to expand, not cold and empty things. Well, some other physicists found that even empty spaces can have the occasional energy fluctuations, and those energy fluctuations are probably what led to our universes and the other universes too.
***Sure, there was the original show, and then Young Sheldon …
****”The universe is a cold and empty place” is ~definitely~ something I wrote in a LiveJournal, circa 2003.
OK, annoying thing no. 1: this passage kind of assumes you have like a basic, working understanding of thermodynamics. Annoying thing no. 2: the author is definitely present in this passage, and seems to accept Carroll and Chen’s theory, but there isn’t a conclusion offered anywhere, making it hard to determine what the main point of the passage is. Annoying thing no. 3: there were a lot of questions about the organization of the passage, when I thought the organization was kind of jumbled and all over the place … entropic, if you will.
And I definitely wasn’t the only one who thought this … the last question on this passage was “removed from scoring,” a measure that the LSAT takes only when the responses from test takers deviate so greatly from the predicted responses that it’s clear something was misleading or unreliable about that question or passage.
• The rest of the passages, though? Not so bad. The first passage was a mash note to the Indus Valley, the oft-overlooked Bronze Age civilization. The passage is about all the cool things we’ve recently learned about Indus Valley, and how that changed some of our assumptions about its demise. The questions were mostly about the details, but as long as you had good tags, you would have been Indus to win this.
• The second was about how this film scholar was stretching when he claims that musicals from the 1930s, like Busby Berkeley’s, were “realistic.” OK, since they brought it up, let’s take a timeout for one of the greatest love songs ever written …
Anyway, this was a classic antithesis passage in which the author really had her knives out for the film scholar. The way she bloodied up this film scholar’s argument, the end result resembled less a musical and more a horror film.
• The third passage was the dreaded comparative passage, but it was in my view, one of the easiest comparative passages in years. Passage A was about how human beings probably lack free will, or that any free will we may have is incredibly circumscribed by a million factors. And, as such, we should remove the idea of “blameworthiness” from criminal law. It all reads like a very unconvincing non-apology for some horrific accident. “Neurological research tells us that, if free will does exist, it has little room in which to operate. As such, blameworthiness is a backward-looking concept that demands the impossible task of untangling the hopelessly complex web of genetics and environment in order to isolate a factor of free will that may or may not exist. In conclusion, I’m sorry I ran over your dog, but I must respectfully disagree with your claim that that I had much choice in the matter.” Passage B picks up pretty much right where passage A left off. Passage B reaches a different conclusion though — human beings have a demonstrable tendency to assign blame, so trying to remove blame from criminal law is impossible. As long as you got that, the questions would have been smooth sailing. Either way, no one is going to blame the LSAT offering a manageable comparative passage.
Logic Games
• OK, let’s go straight to mining game that duped a significant number of test takers. It was the third game. The game told us a mining company would be sending out its engineering team to month-long work trips to one of two mines — the Grayson mine and the Krona mine — or keeping the team on a month-long stay at the company’s headquarters. So it was our job to figure out which months, from March to November, the engineering team would be at Grayson mine, Krona mine, or the company’s HQ. The game told us that the team would spend a total of three months at Grayson mine and three months at Krona mine.
I believe that last detail led some test takers to conclude that this game was a grouping game or a combo game, since I heard from a few people this game was one of those. Making that conclusion would have led to big trouble. I’m starting to feel like this exhortation is going to end up on my tombstone, but let me exclaim it once more: SCHEDULING IS ORDERING! End of story! You got nine months? You got nine slots in your ordering set-up. Line ’em up and don’t over-think it. And, in this game, your players would include three Gs (one for each month spent at Grayson), three Ks (for the three months at Krona), and three Hs (for the three months at HQ).
Now, nine slots is a lot to deal with, and I was actually a little bit stumped on how to best label the slots. I went with 3-11, referring to the number of the month. I have no idea if this was the best approach (I, for one, always forget if June is the sixth or seventh month in the calendar year, and “November” is literally Latin for “ninth month,” despite being the eleventh month). But I’m sort of lazy and didn’t want to write “APR” and “AUG” to distinguish April and August, or “JUN” and “JUL” to distinguish those two months, or “MAR” and “MAY.”
This game wasn’t super difficult, it was just … annoying? And I say that as a person who loves logic games. I will never make sense of the world around me. I will never understand the opposite sex (for male LSAT instructors, women are “hard to get” in more than one way). But logic games? I get those. They make sense to me. They’re my constant. But this one just did a bunch of stuff that really tested my love.
Beyond the annoying set-up, that either required you to write out the names of the months or count from 3 to 11,***** there was the first rule. That rule said, “The team must work for at least one month at headquarters between any two months working at different mines.” A chill version of this game would have said, “The team cannot work in Grayson and Krona mines on consecutive months.” Or, “The team cannot work in Grayson mine in the month immediately before or immediately after any month it works in Krona mine.” Or, even, “Before moving from one mine to the other, the team must work for at least one month at the company headquarters.” In other words, it could have conveyed information to you like a normal person and not something that was Google Translated from ancient Sumerian into French and then into English. And this was an incredibly important rule in this game, too.
*****Shouts to all those who “Come Original” with a different set-up, though.
If you got that rule down though, the game wasn’t too bad. Basically, since Gs and Ks can’t go next to each other, you had to have an “H” buffer between the Gs and Ks. But since you only had three “Hs” to act as buffers, the Gs and Ks had to cluster together in your set-up a little bit. This led to a few important deductions, and two very helpful scenarios.
If, by the way, this game haunts you, and you’d like another try with a similar game, game 3 on the June 2010 exam is very similar to this one.
• Remember my sweaty exhortation that “SCHEDULING IS ORDERING!” from a few paragraphs ago? There are always exceptions to rules like that on the LSAT, and the first game, a combo game, was one such exception. That game had six speakers lecturing at one of six available timeslots — at 1:00, 2:00, or 3:00 (pm, presumably), on either Thursday or Friday. Now, Thursday comes before Friday, so there’s some natural ordering there. But the game didn’t have a single rule about a player having to go on a day before or after another player. Most of the rules, instead, were about grouping players on different days. So, Thursday and Friday were the two groups, with three slots, numbered 1-3, in each.
This game, for the record, was an echo of game 4 on the June 2010 exam. So bully to you if you did that exam before taking the November test.
• Game 2 was a fairly straightforward 1:1 ordering game and game 4 was a manageable, if somewhat difficult, underbooked ordering game. But what linked all of these games? Scenarios. I would have had a lot of trouble doing any of these games without making scenarios. With them, I finished them in around 25 minutes.
Games that benefit from the use of scenarios are all over recent LSATs. On the September 2018 exam, I thought you should make scenarios for all the games. On June 2018, all but one. On December 2017, all. The trend of scenario-based games is, quite frankly, an unmistakable trend on recent LSATs. If you’re not practicing when and how to make scenarios, you’re preparing for a different LSAT than the one you’re going to get.
The Curve
• So, what was the curve, you ask? Most blogs just say “-11” or “-9,” referring to the number of questions you can miss and still earn a 170. This blog will give you more. We’ll give you the number of questions you can miss and get and still earn a 170, a 165, a 160, a 155, and a 150. And we’ll compare that to the same figures for the past five LSATs …

… After the test, we predicted a -10 or -11 curve. And, not to toot our own horns, but we were somehow right on both counts. It is technically a -10 curve, since that was literally the number of scored questions you could miss and still earn a 170. But it’s also kind of a -11 curve, since there was that one question from Reading Comp that was removed from scoring, essentially granting everyone one free miss. So it is literally a -10 or -11 curve, depending on how you look at it. Call us Aaron Judge, the way we’re just nailing these curves.
Anyway, this curve — looking at all the possible scores, was more or less identical to the September 2018 curve. Not the most generous of curves — you’d have to travel back in time to the quite-difficult December 2017 test to find one of those — but not the most miserly either. Given that nothing on this test was glaringly difficult or alarm-raising, I’d say that’s pretty fair.


